Introduction: Why Your Data Pipeline ETL vs ELT Architecture Matters More Than Ever
In 2025, data is no longer just an asset — it is the competitive battlefield. Organizations are collecting petabytes of information from IoT devices, mobile apps, social media platforms, SaaS tools, and transactional databases every single day. But raw data is worthless without a reliable, scalable, and efficient system to move it, transform it, and make it analysis-ready.
That is where data pipeline architecture comes in — and at the heart of every data pipeline debate is a fundamental architectural question: ETL or ELT?
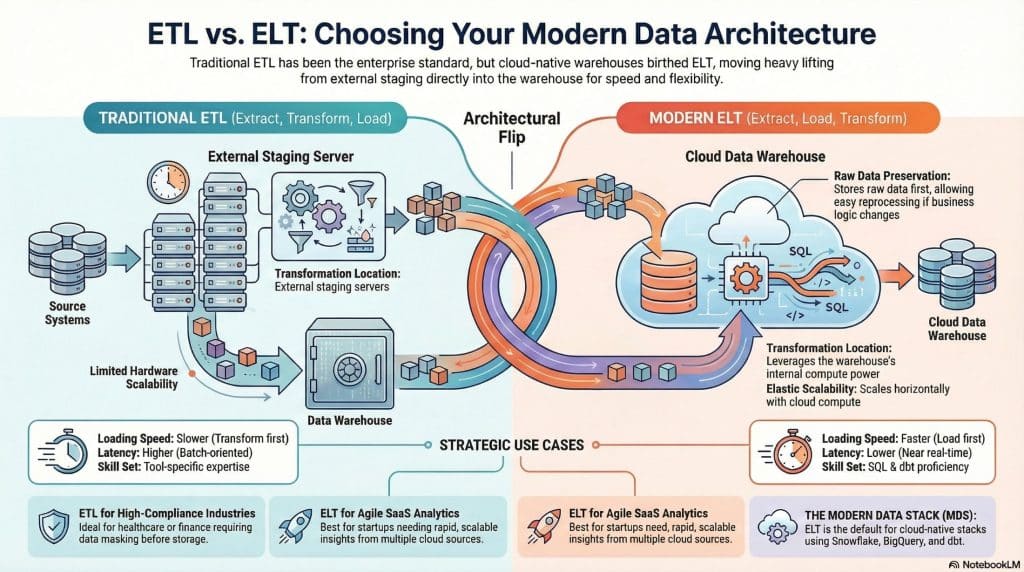
For decades, ETL (Extract, Transform, Load) was the undisputed king of enterprise data integration. But the explosion of cloud data warehouses, columnar storage, and massively parallel processing (MPP) engines has given rise to a powerful challenger: ELT (Extract, Load, Transform) — which flips the traditional sequence and leverages the raw power of the destination system itself to handle transformations.
This guide will walk you through everything you need to know: what ETL and ELT are, how they differ, when to use each, real-world examples from companies like Netflix, Airbnb, and Shopify, and how to build a modern data stack around either approach.
Whether you are a data engineer, a business intelligence analyst, a CTO evaluating tools, or a developer just getting started in the data world — this guide has you covered.
What Is ETL? (Extract, Transform, Load)
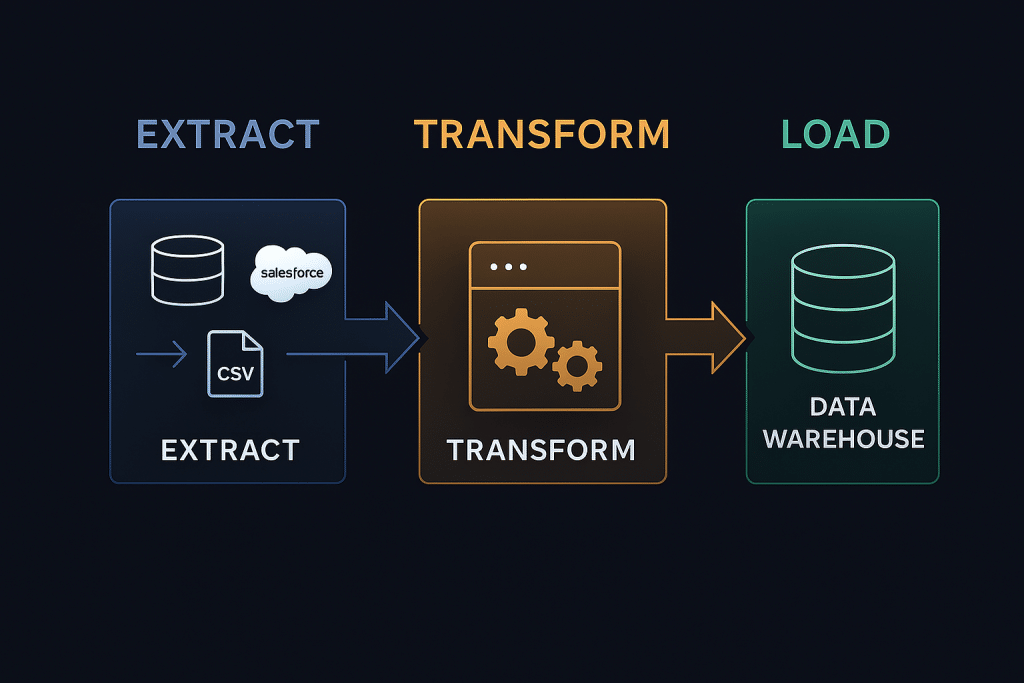
ETL stands for Extract, Transform, Load. It is a three-phase data integration process that has been the backbone of enterprise data warehousing since the 1970s.
Phase 1: Extract
Data is extracted from one or more source systems. These sources can include:
- Relational databases (MySQL, PostgreSQL, Oracle)
- Legacy ERP systems (SAP, PeopleSoft)
- Flat files (CSV, XML, JSON)
- REST APIs and web services
- Streaming sources (Kafka, Kinesis)
The extraction process can be full extraction (dumping the entire dataset each time) or incremental extraction (capturing only new or changed records via change data capture, or CDC).
Phase 2: Transform
Before loading into the target system, data passes through a dedicated transformation engine — often called an ETL server or staging server. This is where the heavy lifting happens:
- Data cleansing: Removing duplicates, fixing null values, standardizing formats
- Data enrichment: Joining records from different sources
- Business logic application: Calculating revenue metrics, applying tax rules, etc.
- Schema mapping: Converting source schemas to match the target data warehouse schema
- Aggregation: Pre-computing summaries and rollups
Phase 3: Load
The cleaned, transformed data is finally loaded into the destination system — typically a data warehouse like Teradata, IBM Db2, or an on-premises Oracle database. The data arrives in a ready-to-query format.
Classic ETL Tools
- Informatica PowerCenter — the enterprise gold standard
- IBM DataStage — widely used in banking and insurance
- Microsoft SSIS (SQL Server Integration Services)
- Talend — open-source ETL with enterprise edition
- Pentaho Data Integration
- Apache NiFi — modern, real-time data flow management
ETL Example: Retail Bank Data Warehouse
A major retail bank needs to consolidate customer data from three sources: a core banking system (Oracle), a loan management system (DB2), and a CRM platform (Salesforce). Each system has different data formats, naming conventions, and customer ID schemas.
An ETL pipeline would:
- Extract customer records from all three systems at 2:00 AM each night
- Transform the data in a staging area: deduplicate records, standardize phone number formats, map customer IDs across systems, calculate aggregate account balances
- Load the fully-prepared, joined, and cleansed dataset into the bank’s Teradata data warehouse by 6:00 AM, ready for branch staff reporting
This worked brilliantly — for decades. But the world of data has changed dramatically.
What Is ELT? (Extract, Load, Transform)
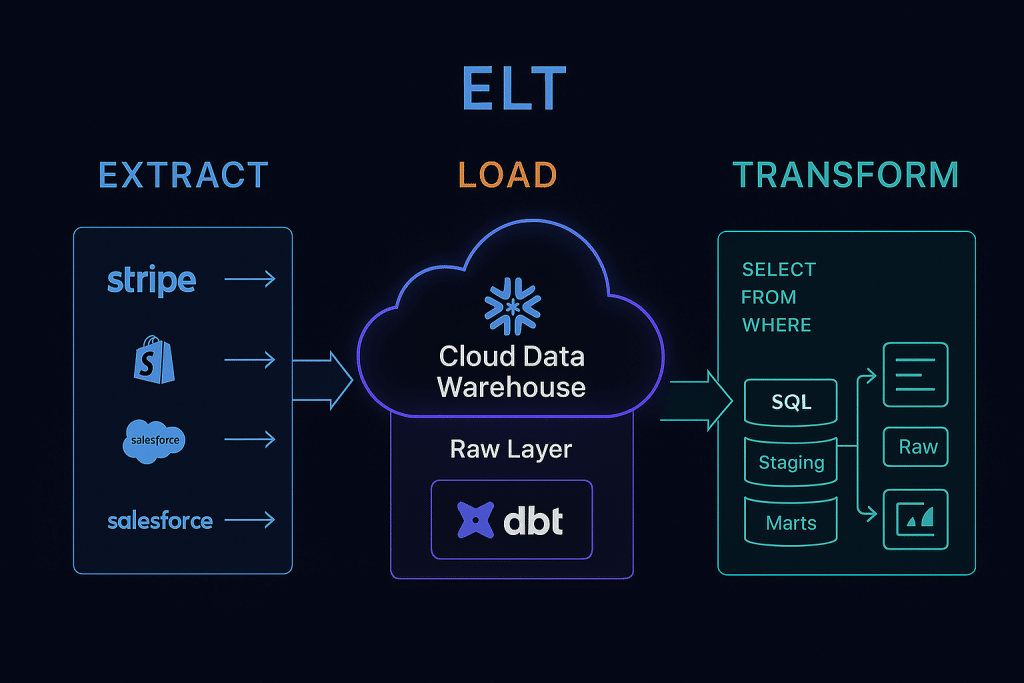
ELT stands for Extract, Load, Transform. It is the modern reinvention of the data pipeline, made possible by the rise of cloud-native data warehouses and the near-infinite compute power they offer.
The key difference is deceptively simple: the order of the last two steps is reversed. Data is loaded into the destination system first — in its raw, unprocessed form — and transformations happen inside the warehouse afterward.
Phase 1: Extract
Just like ETL, data is extracted from source systems. The difference is that ELT tools extract data quickly and with minimal pre-processing — the goal is speed of ingestion, not data quality at this stage.
Phase 2: Load
Raw data is loaded directly into a cloud data warehouse or data lake. Modern ELT destinations include:
- Snowflake — separates storage and compute, scales elastically
- Google BigQuery — serverless, columnar, massively parallel
- Amazon Redshift — AWS’s managed data warehouse
- Databricks Lakehouse — combines data lake + warehouse capabilities
- Azure Synapse Analytics — Microsoft’s unified analytics platform
Raw data typically lands in a raw or staging schema within the warehouse. It is messy, unstructured, and not yet fit for reporting — but it is safely stored and ready for transformation.
Phase 3: Transform
Transformations happen inside the warehouse using SQL-based transformation tools. The most popular tool in this space is dbt (data build tool), which allows data engineers and analysts to write modular, version-controlled SQL transformations that run natively in the warehouse.
Transformation steps typically follow a layered architecture:
- Raw layer: Exact copy of source data, no changes
- Staging layer: Light cleaning, renaming, type casting
- Intermediate layer: Business logic, joins, deduplication
- Marts layer: Final dimensional models ready for BI consumption
Modern ELT Tools
- Fivetran — fully managed, 300+ pre-built connectors
- Airbyte — open-source alternative to Fivetran
- Stitch Data — lightweight ELT for startups
- dbt (data build tool) — SQL-based transformation layer
- Matillion — low-code ELT for cloud warehouses
- AWS Glue — serverless ETL/ELT on AWS
ELT Example: E-commerce Analytics at Scale
An e-commerce company like Shopify or an independent online retailer has data flowing from Shopify (orders), Stripe (payments), Facebook Ads (marketing spend), Google Analytics (web traffic), and Zendesk (support tickets).
An ELT pipeline would:
- Extract raw data from all five sources using Fivetran connectors, running every 15 minutes
- Load all raw data into Snowflake’s raw schema — fast, cheap, and complete
- Transform the data using dbt models: create a unified customer 360 view, calculate customer lifetime value (CLV), build a marketing attribution model, and create revenue dashboards — all inside Snowflake using its MPP compute engine
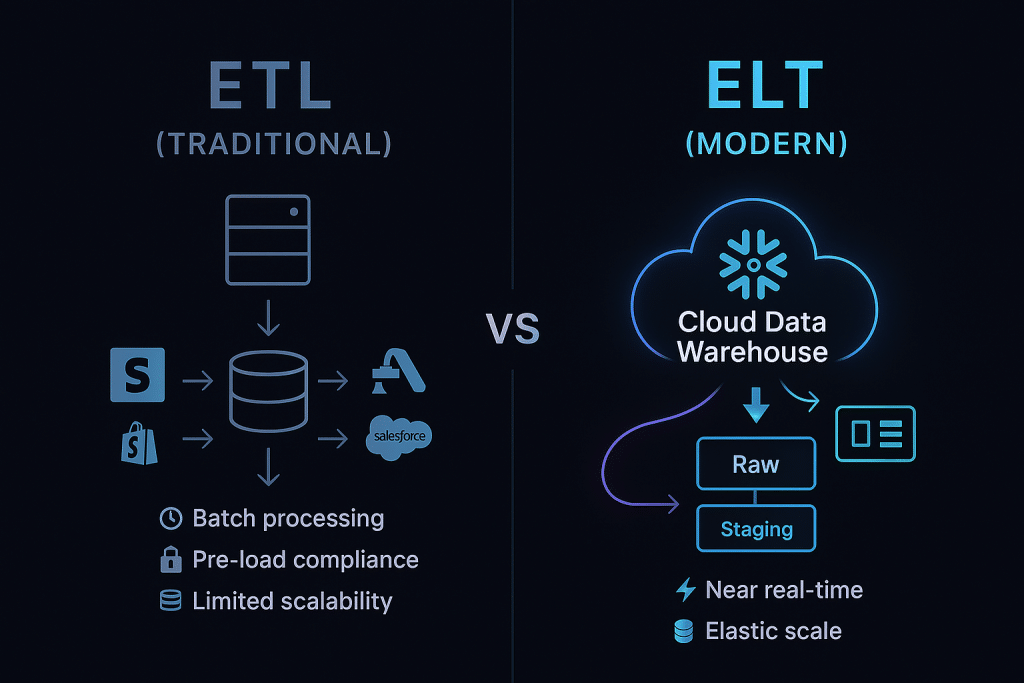
ETL vs ELT: Head-to-Head Comparison
| Feature | ETL | ELT |
|---|---|---|
| Transformation Location | External staging server | Inside destination warehouse |
| Data Loaded | Clean, structured data | Raw, unprocessed data |
| Speed of Loading | Slower (transform first) | Faster (load first) |
| Scalability | Limited by ETL server capacity | Scales with warehouse compute |
| Raw Data Preservation | No — transformed before load | Yes — raw data always available |
| Best For | Structured, compliance-heavy data | Cloud-native, agile analytics |
| Cost Model | ETL server + warehouse licensing | Warehouse compute costs |
| Skill Requirements | ETL tool expertise + scripting | SQL + dbt proficiency |
| Latency | Higher (batch-oriented) | Lower (near real-time possible) |
| Data Reprocessing | Difficult — must re-run pipeline | Easy — raw data always preserved |
| Compliance/Privacy | Easier to mask before load | Requires careful warehouse governance |
| Popular Tools | Informatica, SSIS, Talend | Fivetran + dbt + Snowflake |
Deep Dive: Key Differences Between ETL and ELT
1. Where Transformation Happens
This is the defining difference. In ETL, a dedicated transformation engine (on-premises or virtual) handles all the heavy lifting before data ever touches the warehouse. This was necessary when storage was expensive and warehouses lacked powerful compute.
In ELT, the destination warehouse IS the transformation engine. Cloud warehouses like Snowflake and BigQuery can spin up hundreds of parallel compute nodes on demand, running complex SQL transformations in seconds that would take ETL servers hours.
2. Data Latency and Freshness
ETL is predominantly batch-oriented. Transformations run on a schedule — nightly, hourly, or at best every 15–30 minutes. This introduces latency between when an event happens in the real world and when it appears in your dashboard.
ELT enables much lower latency. Raw data can be continuously streamed into the warehouse (using tools like Kafka + ksqlDB or Fivetran’s Change Data Capture), and lightweight transformations can run in near real-time. Companies like Netflix use streaming ELT to update recommendation models within minutes of a user watching something.
3. Data Storage and the “Raw Data” Advantage
One of the most underrated advantages of ELT is raw data preservation. In ETL, once data is transformed and loaded, the original raw form is often discarded. If your business logic changes, you need to re-run the entire extraction and transformation pipeline — expensive and time-consuming.
In ELT, raw data always lives in the warehouse. If a business analyst realizes they need to redefine how “active customer” is calculated, they simply update the dbt model and rerun the transformation. No data re-extraction required.
4. Scalability
ETL scalability is hardware-bound. If your data volumes grow 10x, you need to upgrade or add ETL servers — capital-intensive and operationally complex.
ELT scalability is elastic. Cloud warehouses scale horizontally on demand. Processing 1 TB vs 1 PB of data simply means paying for more compute — no infrastructure changes needed.
5. Security and Compliance
This is where ETL still holds an advantage in certain scenarios. In heavily regulated industries (healthcare with HIPAA, finance with PCI-DSS), ETL allows you to mask, anonymize, or filter sensitive fields before they ever enter the target system. This can simplify compliance audits.
In ELT, sensitive data enters the warehouse in raw form, requiring robust column-level security, dynamic data masking, and row-level access policies within the warehouse itself — capabilities that tools like Snowflake and BigQuery now offer, but which require careful configuration.
Real-World Use Cases: ETL vs ELT in Practice
When to Choose ETL
Use Case 1: Healthcare Data Integration (HIPAA Compliance)
A hospital network needs to consolidate patient records from EMR systems across 50 clinics. Patient data (SSNs, diagnoses, medications) must be anonymized and de-identified before entering any analytics system. ETL’s pre-load transformation stage makes this straightforward — PII never touches the warehouse in raw form.
Use Case 2: Legacy System Modernization
A manufacturing company with 30-year-old mainframe systems running COBOL needs to feed data into a modern BI platform. The source data is in proprietary formats that require heavy parsing and format conversion before becoming usable. ETL middleware with specialized connectors handles this complexity.
Use Case 3: On-Premises Data Warehouse
Organizations that cannot migrate to cloud due to regulatory, contractual, or technical constraints continue to operate on-premises Teradata or Oracle warehouses where ETL remains the natural fit.
When to Choose ELT
Use Case 1: SaaS Analytics Stack (Modern Data Stack)
A B2B SaaS company (think HubSpot, Intercom, or similar) aggregates data from Salesforce CRM, HubSpot Marketing, Stripe billing, and Amplitude product analytics. Fivetran syncs all sources into Snowflake every 30 minutes; dbt models build marketing attribution, MRR/ARR dashboards, and churn prediction features. The entire stack is cloud-native, low-maintenance, and highly scalable.
Use Case 2: Real-Time Personalization (Netflix/Spotify Style)
Streaming companies like Netflix extract user behavior events (plays, pauses, ratings, searches) continuously into BigQuery or Databricks. ELT pipelines transform these events into feature stores that feed machine learning models — powering the recommendation engine that drives 80% of content discovery.
Use Case 3: Startup Analytics
A Series A startup with a small data team needs to stand up analytics quickly. Using Airbyte (open-source) + BigQuery + dbt, a single data engineer can build a production-grade analytics platform in days — no ETL server to provision, no complex middleware licensing.
The Modern Data Stack: Where ELT Dominates
The term “Modern Data Stack” (MDS) has become synonymous with cloud-native ELT architecture. The canonical modern data stack looks like this:
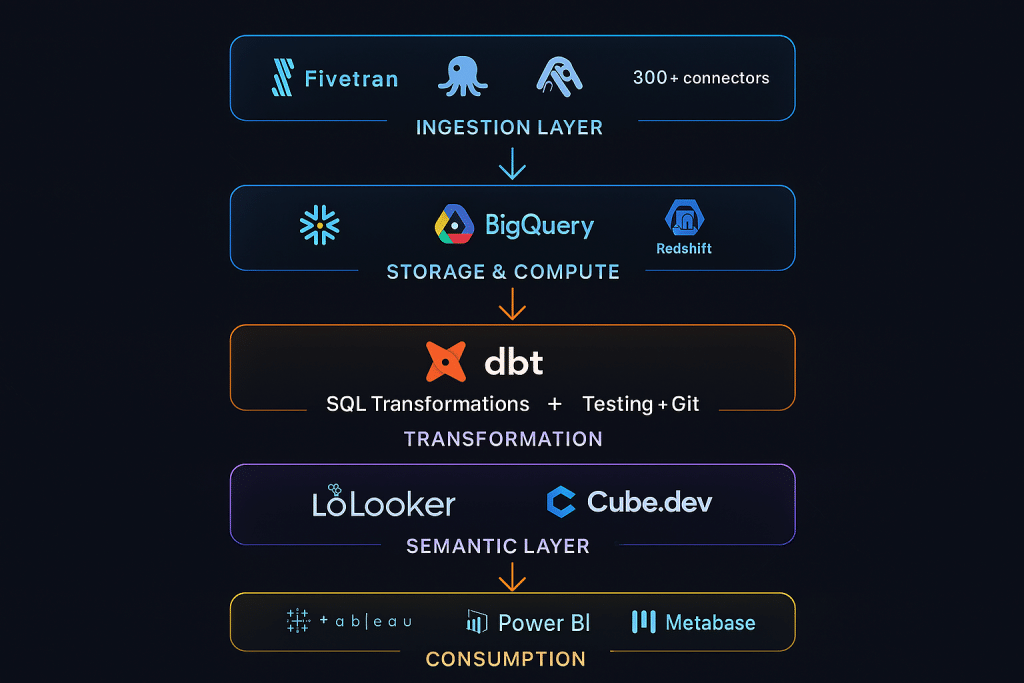
Ingestion Layer → Storage/Compute Layer → Transformation Layer → Semantic Layer → Consumption Layer
- Ingestion: Fivetran, Airbyte, Stitch (connectors to 300+ sources)
- Storage/Compute: Snowflake, BigQuery, Redshift, Databricks
- Transformation: dbt (data build tool) — the linchpin of the modern stack
- Semantic Layer: Looker (LookML), dbt Semantic Layer, Cube.dev
- Consumption: Tableau, Power BI, Looker, Metabase, Mode Analytics
This stack is beloved because each component does one thing extremely well, they compose beautifully together, and they scale independently. It has driven a tidal wave of adoption among data-forward companies since 2018.
dbt: The Game-Changer for ELT Transformations
No discussion of modern ELT is complete without a dedicated mention of dbt (data build tool). Originally built by Fishtown Analytics (now dbt Labs) and released as open-source in 2016, dbt has become the de facto standard for the transformation layer in ELT pipelines.
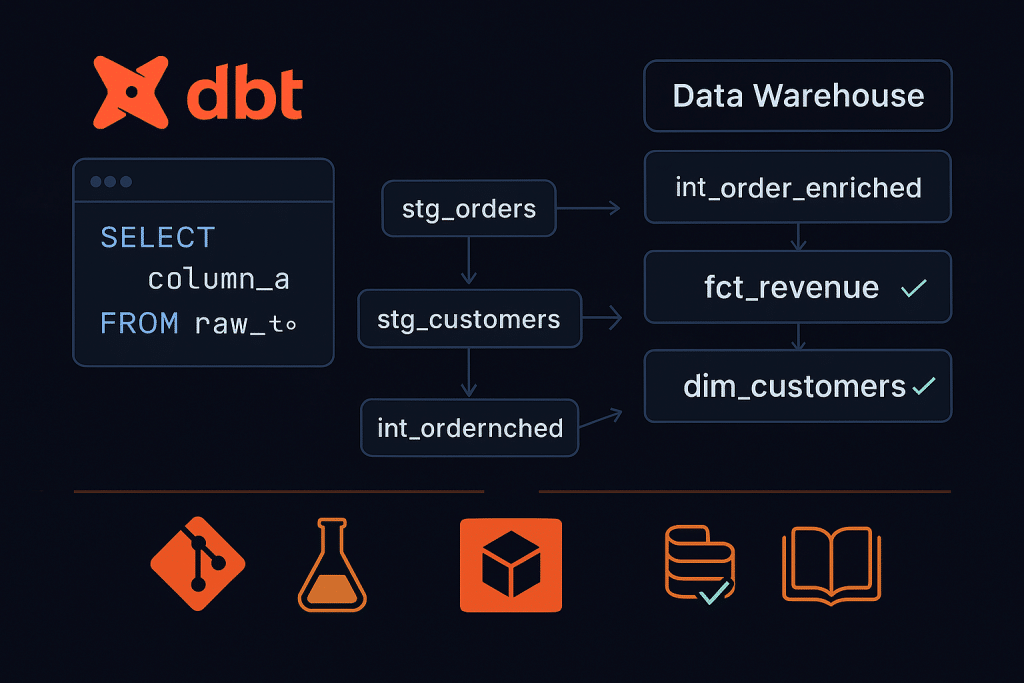
What Makes dbt Special?
SQL-first: dbt uses SQL — the language every analyst knows — rather than requiring Python or Scala expertise.
Version control: dbt models are SQL files that live in Git. Every transformation is code-reviewed, versioned, and auditable.
Testing: dbt ships with built-in data testing — assert that primary keys are unique, foreign keys are valid, no nulls in critical fields.
Documentation: dbt auto-generates a data catalog with lineage graphs showing exactly how every model is built.
Modularity: Transformations are written as modular SQL SELECT statements that compose into a DAG (Directed Acyclic Graph) of dependencies.
A simple dbt model looks like this:
sql
WITH orders AS (
SELECT * FROM {{ ref('stg_orders') }}
),
customers AS (
SELECT * FROM {{ ref('stg_customers') }}
)
SELECT
c.customer_id,
c.email,
COUNT(o.order_id) AS total_orders,
SUM(o.order_amount) AS lifetime_value,
MAX(o.order_date) AS last_order_date
FROM customers c
LEFT JOIN orders o ON c.customer_id = o.customer_id
GROUP BY 1, 2
This model runs natively in Snowflake, BigQuery, or Redshift — no dedicated server required.
ETL vs ELT: Performance Considerations
Data Volume
For small to medium data volumes (< 100 GB/day), ETL and ELT perform comparably. ETL’s pre-load transformation keeps the warehouse clean but introduces latency.
For large data volumes (100 GB–1 PB+/day), ELT wins decisively. Cloud warehouses like Snowflake with multi-cluster compute, or BigQuery with serverless execution, process terabytes of raw data in seconds using massively parallel SQL. No ETL server can match this throughput.
Query Performance
ETL historically produced better query performance because data arrived pre-aggregated and pre-joined. Modern ELT achieves comparable performance through materialization strategies — dbt models can be configured as tables (pre-computed), views (computed on query), or incremental models (only process new records), achieving the same result with far more flexibility.
Cost
ETL costs are dominated by ETL tool licensing (Informatica alone can run $100K+/year for enterprise) plus dedicated server infrastructure.
ELT costs are warehouse-compute-driven. Snowflake charges by the second of compute used; BigQuery charges per TB scanned. For most organizations, the modern ELT stack is significantly cheaper — though it requires disciplined query optimization to avoid runaway costs.
Emerging Trends: Streaming, Reverse ETL, and the Future
Streaming ETL/ELT with Apache Kafka and Spark
Traditional pipelines are batch-oriented. The next frontier is streaming data pipelines that process events in real time:
- Apache Kafka as the event backbone — capturing clickstreams, IoT sensor data, payment events
- Apache Spark Structured Streaming or Apache Flink for real-time transformations
- Kafka Streams for lightweight in-flight processing
Companies like Uber, LinkedIn, and Lyft process billions of events per day through streaming architectures where the ETL/ELT distinction blurs — transformation and loading happen continuously and simultaneously.
Reverse ETL: Closing the Loop
A fascinating new category called Reverse ETL has emerged. Traditional pipelines move data INTO the warehouse. Reverse ETL moves data OUT — back into operational systems.
Example: Your data warehouse has calculated that Customer X has a high churn probability score. Reverse ETL tools (Census, Hightouch, Polytouch) push this score back into Salesforce, triggering a customer success manager workflow to reach out proactively.
Leading Reverse ETL tools: Census, Hightouch, Grouparoo (open-source)
AI-Powered Data Pipelines
The latest evolution integrates large language models and AI agents into the pipeline:
- Auto-generating dbt models from natural language descriptions
- AI-driven data quality monitoring that detects anomalies
- LLM-powered schema mapping for novel data sources
- Automated pipeline documentation and metadata generation
Tools like dbt Copilot, Monte Carlo, and Soda are leading this charge.
Choosing the Right Architecture: A Decision Framework
Ask yourself these questions when choosing between ETL and ELT:\
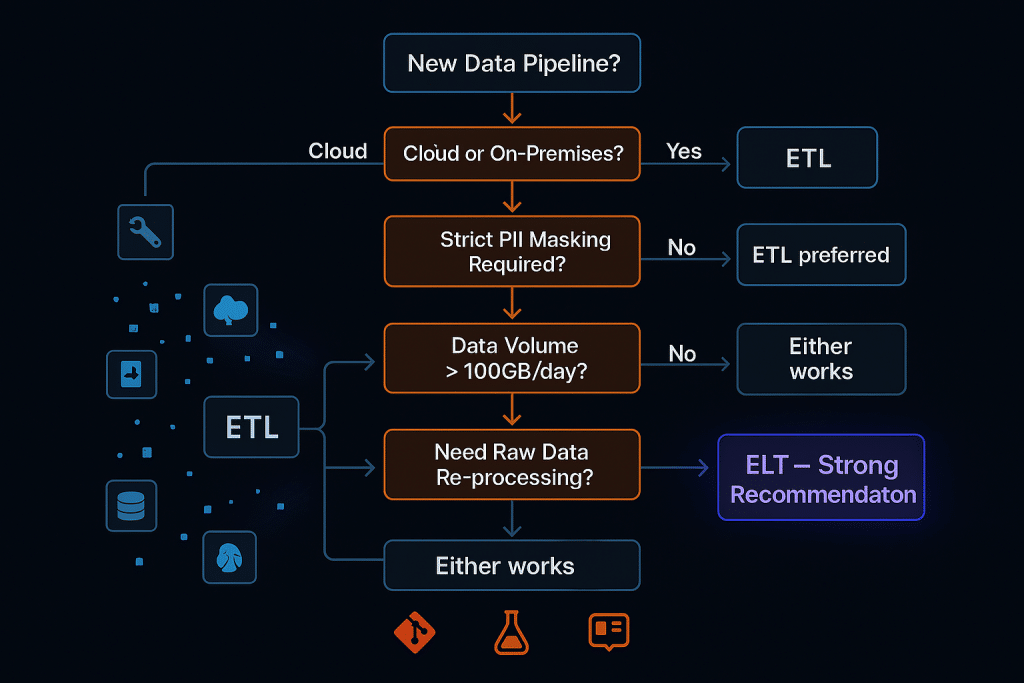
1. Are you on-premises or cloud?
On-premises → ETL (cloud-native ELT may not be viable)
Cloud → ELT (strong default choice)
2. What are your compliance requirements?
Strict PII masking before storage → ETL (or ELT with careful governance)
Standard compliance → ELT with warehouse-level security
3. What is your data volume?
< 10 GB/day → Either works
10 GB–1 TB/day → ELT preferred
1 TB+/day → ELT required
4. What is your team’s skill set?
ETL tool experts (Informatica, SSIS) → ETL
SQL-first analysts and engineers → ELT + dbt
5. Do you need historical raw data re-processing?
Yes → ELT (raw data preservation is built-in)
No → Either works
6. What is your latency requirement?
Near real-time (< 5 minutes) → ELT with streaming
Batch (daily/hourly) → Either works
Summary: ETL vs ELT — Which Wins?
There is no universal winner — the right choice depends on your specific context. But here is the honest industry consensus in 2025:
For new, cloud-native data architectures: ELT is the default choice for the vast majority of organizations. The modern data stack (Fivetran + Snowflake + dbt) is faster to build, cheaper to operate, more flexible, and more empowering for analytics teams.
For legacy enterprise environments: ETL remains essential for organizations with on-premises warehouses, mainframe source systems, complex legacy data formats, or strict pre-load compliance requirements.
The hybrid reality: Many mature data organizations operate both. ETL handles sensitive, compliance-heavy pipelines feeding curated data marts; ELT handles high-volume, agile analytics workloads feeding self-service BI.
The key is not picking a "winner" — it is deeply understanding your data, your team, your regulatory environment, and your business goals, then architecting accordingly.
Frequently Asked Questions (FAQ)
Q1: Is ELT always better than ETL in 2025?
A: Not always. ELT is the preferred choice for most modern, cloud-native data stacks due to its scalability, flexibility, and raw data preservation. However, ETL remains superior in scenarios requiring strict pre-load data masking (e.g., HIPAA compliance), integration with on-premises systems, or highly structured legacy data formats that require complex parsing before being warehouse-compatible.
Q2: What is the main advantage of ELT over ETL?
A: The biggest advantage is scalability and flexibility. ELT leverages the massive parallel compute power of cloud data warehouses (Snowflake, BigQuery, Redshift) to run transformations at scale. It also preserves raw data, making it easy to re-transform when business logic changes — without re-extracting from source systems.
Q3: Can I use both ETL and ELT in the same organization?
A: Absolutely — and many enterprise organizations do. Sensitive, compliance-heavy pipelines often use ETL to mask PII before data enters analytics systems, while high-volume product analytics and marketing data use ELT for speed and agility. The two approaches are complementary, not mutually exclusive.
Q4: What is dbt and why is it so popular in ELT?
A: dbt (data build tool) is an open-source SQL transformation framework that runs entirely inside your data warehouse. It is popular because it brings software engineering best practices (version control, testing, documentation, modularity) to SQL-based data transformation. It enables analysts to own the transformation layer without needing Python or Scala expertise, democratizing data engineering.
Q5: How does ELT handle sensitive data and GDPR/HIPAA compliance?
A: Modern ELT platforms handle compliance through warehouse-level controls: column-level security, dynamic data masking, row-level access policies, and data tokenization. Cloud warehouses like Snowflake, BigQuery, and Redshift have mature compliance certifications (SOC 2, HIPAA, PCI-DSS). However, organizations in highly regulated industries should carefully design their governance model when choosing ELT.
Q6: What is Reverse ETL and how does it fit in modern data architecture?
A: Reverse ETL is the practice of pushing transformed, enriched data from the warehouse back into operational business tools (Salesforce, HubSpot, Marketo, Zendesk). It "closes the loop" of the data lifecycle — analytics insights flow back into the systems where business teams work. Leading Reverse ETL tools include Census and Hightouch.
Q7: Is Apache Spark an ETL or ELT tool?
A: Apache Spark can function as both, depending on how it is configured. Used as a standalone processing engine that transforms data before loading it into a destination, it operates in ETL mode. When Spark is embedded within a data lakehouse (like Databricks) and used to transform data that has already been ingested raw, it operates in ELT mode. Modern Spark usage increasingly aligns with ELT/lakehouse patterns.
Q8: What does a modern data stack (MDS) look like?
A: A typical modern data stack comprises: (1) Ingestion: Fivetran or Airbyte for 300+ data source connectors; (2) Storage/Compute: Snowflake, BigQuery, or Databricks as the cloud data warehouse; (3) Transformation: dbt for SQL-based, version-controlled data models; (4) Semantic Layer: Looker or Cube.dev for metric definitions; (5) BI/Consumption: Tableau, Power BI, or Metabase for dashboards and self-service analytics.
Q9: How does streaming fit into ETL and ELT architectures?
A: Streaming adds a real-time dimension to both architectures. Streaming ETL uses tools like Apache Flink or Spark Structured Streaming to transform events in flight before writing to the destination. Streaming ELT ingests raw events continuously into the warehouse (often via Kafka connectors) and transforms them with SQL or dbt incremental models. The choice depends on latency requirements and the complexity of real-time transformations needed.
Q10: What is the difference between a data warehouse, data lake, and data lakehouse?
A: A data warehouse stores structured, processed data optimized for SQL analytics (Snowflake, Redshift). A data lake stores raw, unstructured, and semi-structured data at low cost (S3, ADLS, GCS). A data lakehouse combines both — storing raw data at lake-scale while enabling warehouse-quality SQL analytics on top (Databricks, Apache Iceberg on BigQuery). ELT architectures work beautifully with lakehouses, which represent the leading edge of modern data infrastructure.